


- KI in der Medizin: Vor- und Nachteile
- Sechs wichtige Anwendungsbereiche von KI in der Medizin
- Verbesserte Diagnosemethoden
- Individuelle Behandlungsansätze
- Einsatz von Robotern und Technologie
- KI und Datenanalyse in der Forschung
- Innovative Telemedizin
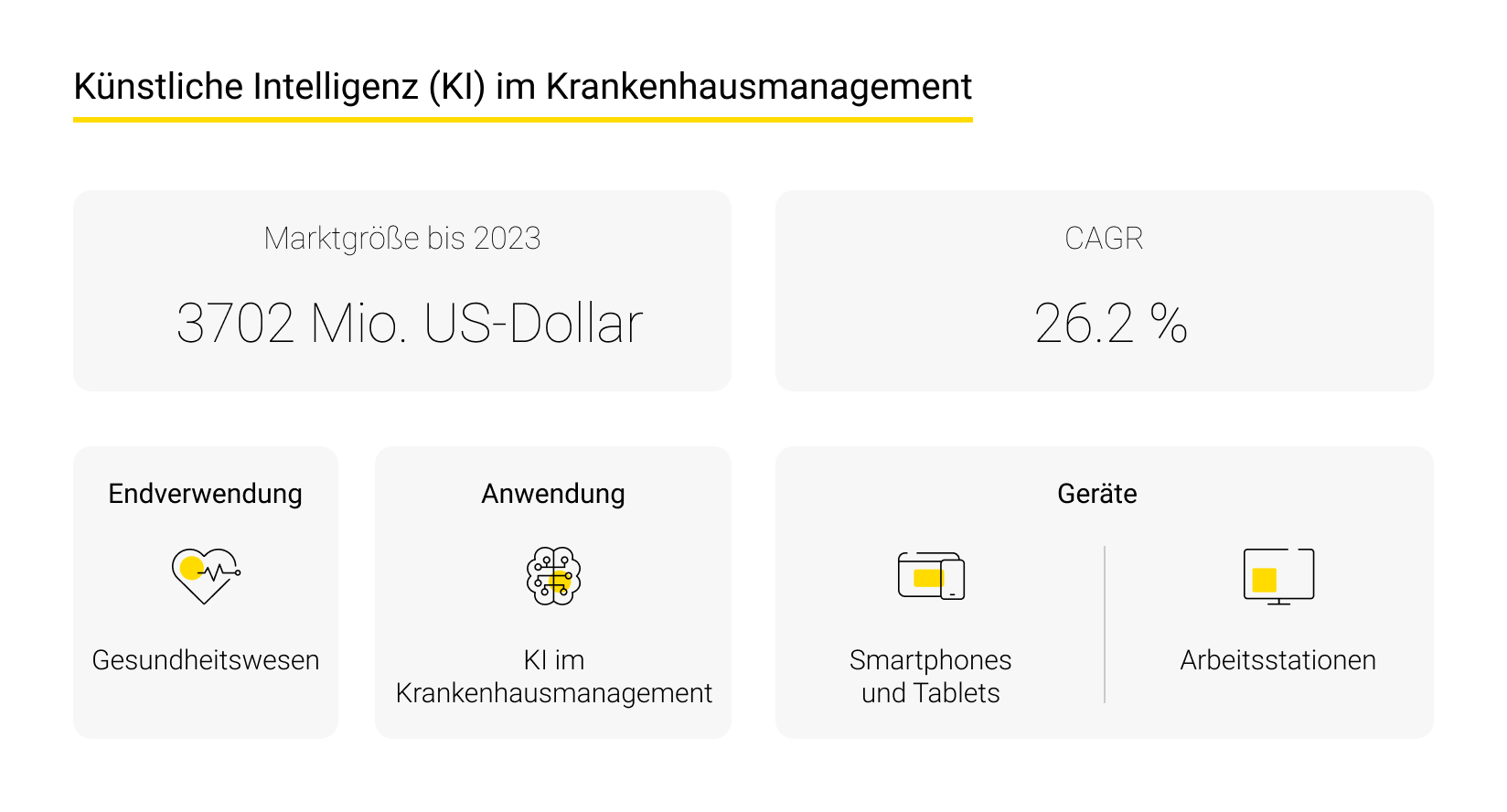
- Intelligente Tools in der Krankenhausverwaltung und Ressourcenoptimierung
- KI als Zukunft der Medizin
- Fazit
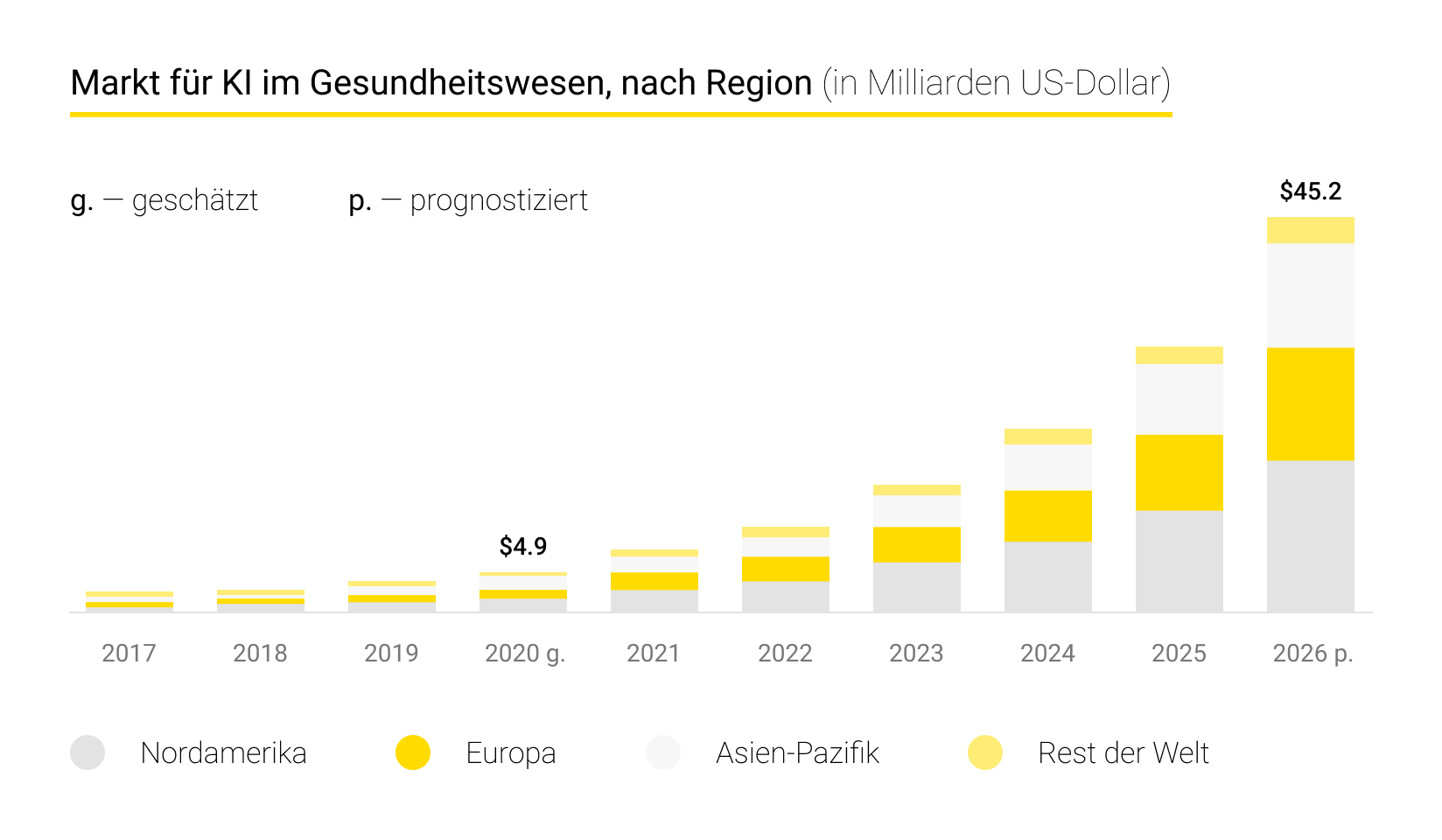
Künstliche Intelligenz in der Medizin ist heutzutage ein sehr wichtiges Thema. Sie treibt eine tiefgreifende Transformation voran und eröffnet enorme Potenziale. Laut Statista wird der globale Umsatz mit KI in dieser Branche bis 2027 voraussichtlich auf 67 Milliarden US-Dollar steigen.
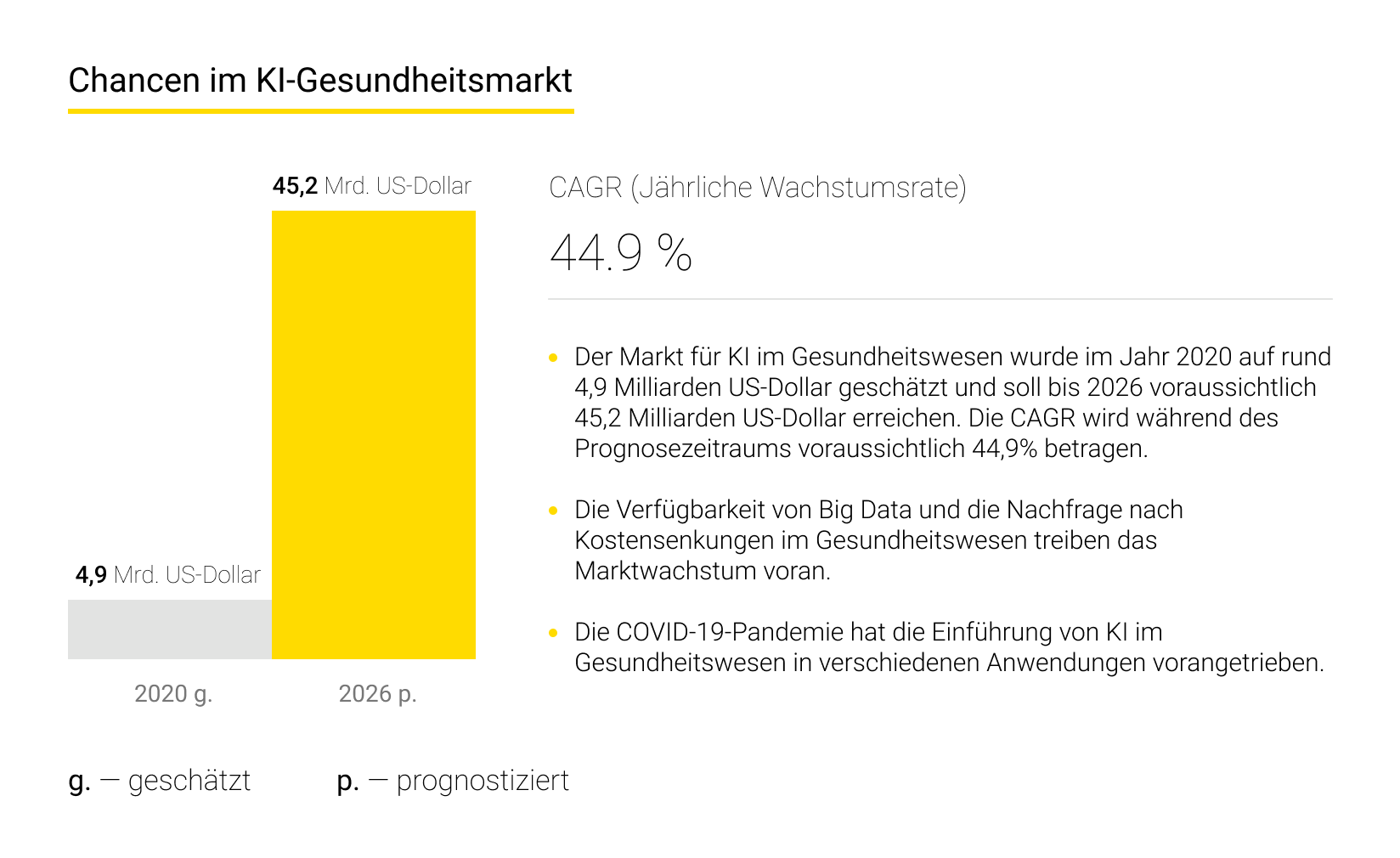
In diesem Beitrag zeigen die Experten von Andersen, wie künstliche Intelligenz zu besseren Gesundheitsergebnissen beiträgt.
KI in der Medizin: Vor- und Nachteile
Intelligente Technologie verändert die Branche nachhaltig. Die Verbesserung der Patientenversorgung, effizientere Abläufe und Fortschritte in der medizinischen Forschung sind deutliche Belege dafür. Dennoch gibt es einige wesentliche Aspekte, die beachtet werden sollten.
Beginnen wir mit den Vorteilen von KI in der Medizin:
- Präzisere Diagnosen
Es werden große Datenmengen analysiert, um Muster oder frühe Krankheitsanzeichen zu identifizieren. Solche feinen Details sind für medizinische Fachkräfte normalerweise schwer zu erkennen.
- Individuelle Therapiekonzepte
Durch die Analyse von Gesundheitsinformationen, genetischen Profilen und medizinischen Historien werden personalisierte Behandlungspläne entwickelt, die auf die individuellen Gegebenheiten jedes Einzelnen abgestimmt sind.
- Unterstützung bei der Pflege
Kliniken setzen virtuelle Assistenten und Chatbots ein, die Patientenfragen beantworten, Informationen bereitstellen und so das Pflegepersonal entlasten.
- Optimierte Forschungsprozesse
KI verkürzt die Zeitspanne für die Medikamentenentwicklung, indem sie große Datenbanken analysiert, potenzielle Wirkstoffkandidaten identifiziert und Wechselwirkungen vorhersagt.
- Effiziente klinische Entscheidungsfindung
Durch die Echtzeitanalyse von Patientendaten und den Abgleich mit medizinischen Wissensdatenbanken unterstützen KI-Tools Fachkräfte bei fundierten, datenbasierten Entscheidungen.
Und hier sind einige der wichtigsten Nachteilen:
- Datenschutz und Sicherheit
Der Einsatz von KI erfordert den Umgang mit sensiblen Patientendaten. Dies wirft Fragen zum Datenschutz, zur Cybersicherheit und zum Schutz vor unbefugtem Zugriff auf.
- Bias und ethische Fragen
KI-Modelle liefern verzerrte Ergebnisse, wenn sie auf unausgewogenen oder nicht repräsentativen Daten basieren. Das kann Ungleichbehandlungen oder fehlerhafte Diagnosen begünstigen.
- Weniger menschliche Interaktion
Digitale Tools können den direkten Kontakt zwischen Patienten und Pflegekräften reduzieren, was Einfluss auf die zwischenmenschliche Bindung haben könnte.
- Regulatorische und rechtliche Komplexität
Die Einführung von KI in die Medizin erfordert ein tiefes Verständnis rechtlicher Rahmenbedingungen und die konsequente Einhaltung ethischer Standards.
- Abhängigkeit von Datenqualität und -verfügbarkeit
Smarte Modelle benötigen umfangreiche, qualitativ hochwertige und gut annotierte Datensätze – diese sind im Gesundheitswesen nicht immer in ausreichendem Maß verfügbar.
- Wandel auf dem Arbeitsmarkt
Da KI bestimmte wiederkehrende Aufgaben übernimmt, werden bestimmte Rollen verändert oder ersetzt. Gleichzeitig entstehen neue Qualifikationen.

Alle diese Vor- und Nachteile von KI in der Medizin hängen stark vom jeweiligen Anwendungsbereich, dem Kontext und einer verantwortungsvollen Implementierung ab.
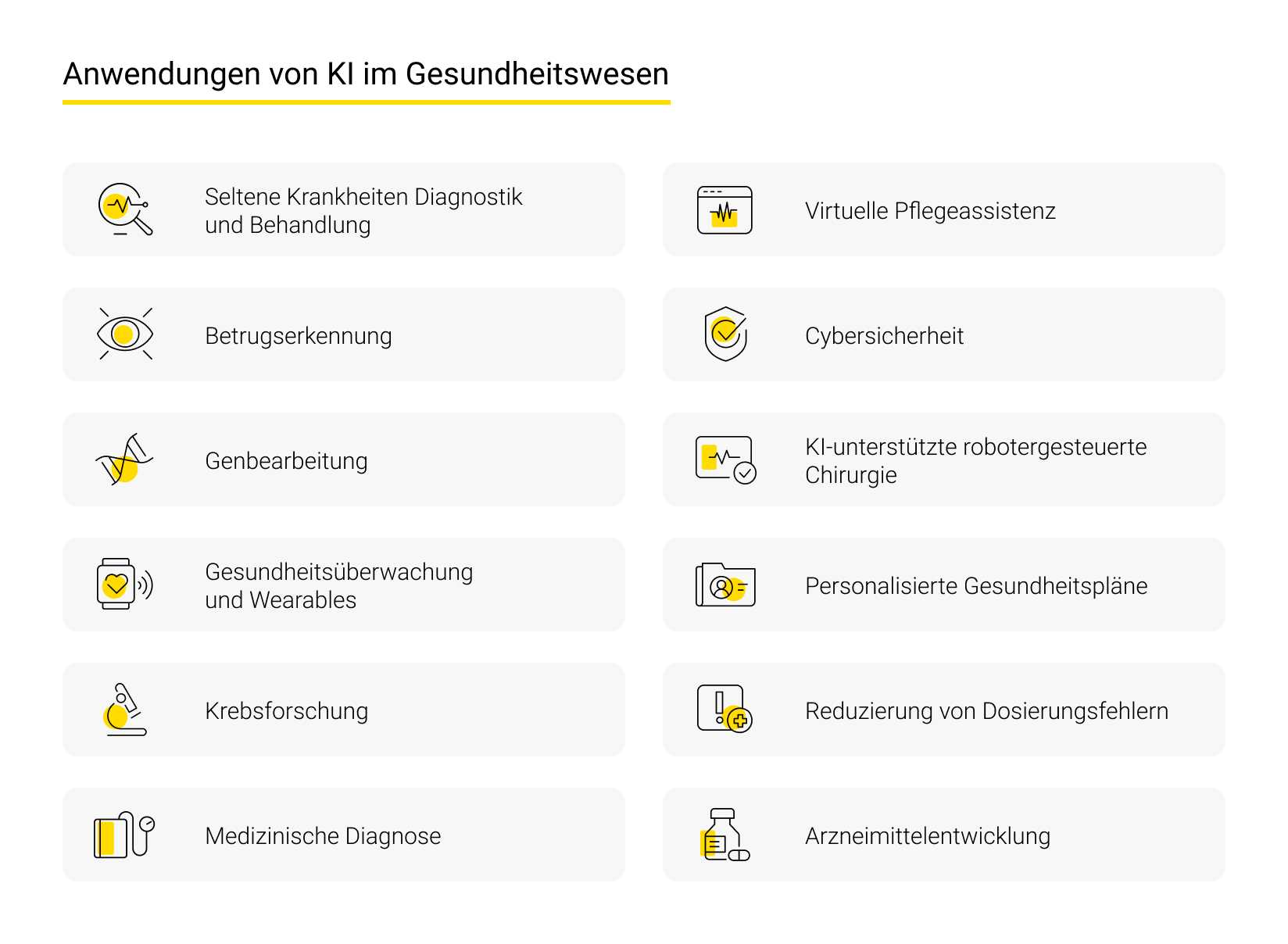
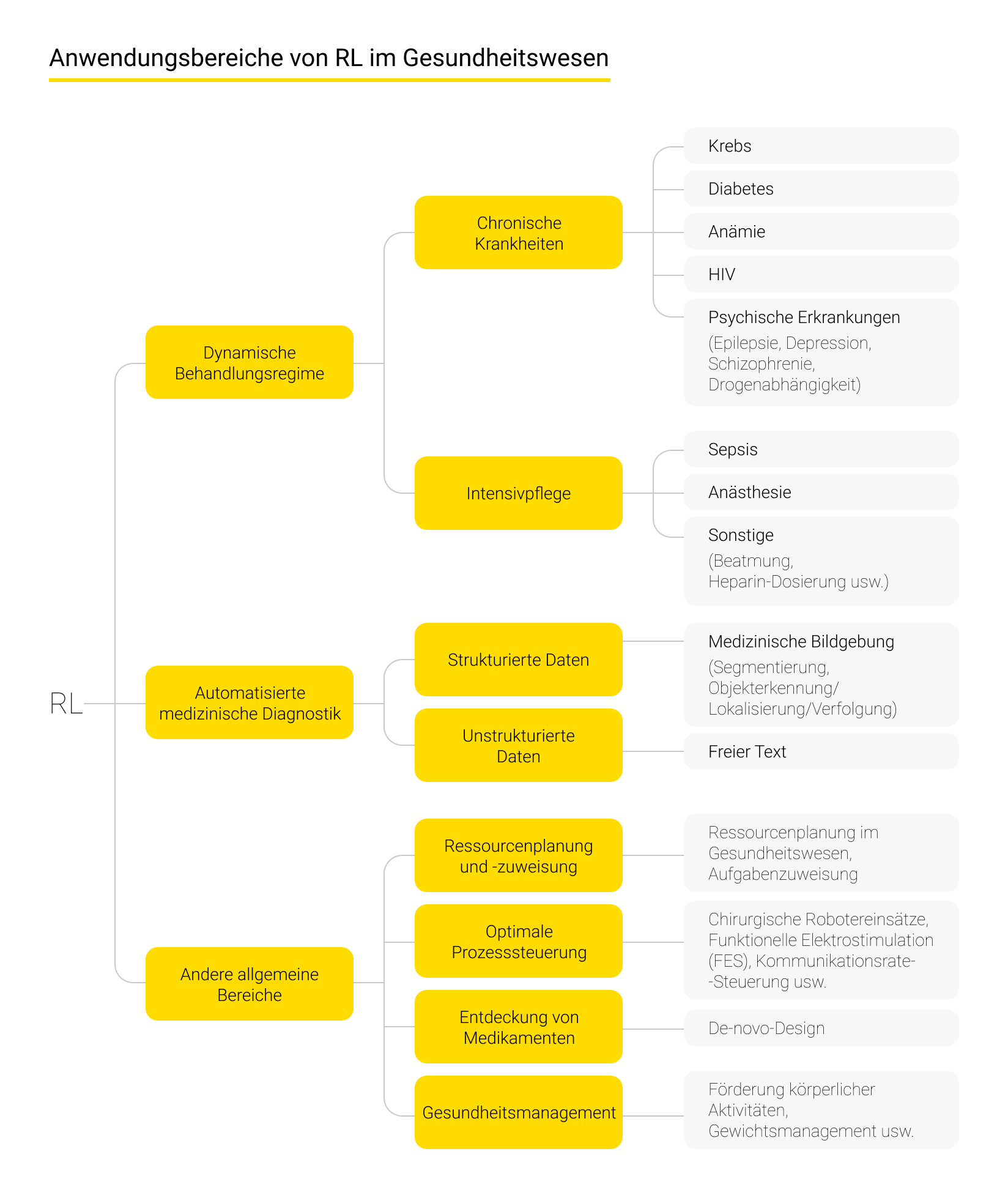
Sechs wichtige Anwendungsbereiche von KI in der Medizin
KI eröffnet vielfältige Möglichkeiten – von effizienteren Arbeitsabläufen bis hin zu verbesserter Behandlung und Pflege.
Schauen wir uns sechs prägnante Beispiele für KI in der Medizin an.
Verbesserte Diagnosemethoden
Der Einsatz von KI im Gesundheitswesen ermöglicht schnelle Diagnostik mit höchster Präzision. Seltene Krankheiten werden in frühen Stadien identifiziert oder diagnostiziert – früher war das eine große Herausforderung.
Indem umfangreiche Daten wie medizinische Bilder, Biosignale, Vitalwerte, Krankengeschichte und Laborergebnisse ausgewertet werden, erhalten Ärzte wertvolle Erkenntnisse. Diese tiefgehende Auswertung hilft dabei, schneller und präziser Behandlungspläne zu entwickeln.
Mithilfe von KI lassen sich bislang unerkannte Zusammenhänge und diagnostische Indikatoren aufdecken. Dies ermöglicht es Gesundheitsdienstleistern, schneller zu reagieren und Patienten einen rascheren Zugang zu spezialisierter Behandlung zu verschaffen. Besonders bei seltenen Erkrankungen können dadurch die Prognosen verbessert werden.
Der Fortschritt im ML-Bereich bringt erhebliche Vorteile für die Diagnostik. KI kann die Präzision, Geschwindigkeit und Effizienz von Vorhersagen steigern. Durch die Auswertung verschiedener Datentypen – etwa medizinischer Bilder, Biosignale und demografischer Daten – erhält man ein ganzheitliches Bild des Gesundheitszustands eines Patienten. Dadurch sinkt das Risiko von Fehldiagnosen und die Genauigkeit der Diagnosen wird erhöht.
Dies hilft Kliniken und Krankenhäusern, den Krankheitsverlauf effizienter zu überwachen und ermöglicht eine effektivere Behandlung von chronischen Erkrankungen.
Gleichzeitig automatisieren digitale Systeme viele Routineaufgaben, sodass Fachkräfte mehr Zeit für komplexe Aspekte der Patientenversorgung haben.
Individuelle Behandlungsansätze
Ein weiterer Einsatz von KI im Gesundheitswesen zeigt sich in der personalisierten Medizin. Sie ermöglicht maßgeschneiderte Behandlungspläne. Kliniken entwickeln individuelle Therapieansätze, die Faktoren wie die Krankengeschichte, das genetische Profil und sogar Lebensgewohnheiten berücksichtigen. Ärzte können wertvolle Erkenntnisse aus umfangreichen Datensätzen gewinnen, um Behandlungspläne gezielt anzupassen. Dadurch wird nicht nur die Wirksamkeit der Behandlung erhöht, sondern auch das Risiko von Nebenwirkungen minimiert.
KI hilft dabei, fundierte Therapieempfehlungen zu generieren. Indem sie umfassende Patientendaten analysiert – darunter medizinische Aufzeichnungen, genetische Informationen, Reaktionsmuster auf Behandlungen und Echtzeit-Überwachungsdaten – erstellt sie evidenzbasierte Empfehlungen, die auch Wechselwirkungen zwischen Medikamenten und individuelle Unterschiede im Ansprechen auf die Therapie berücksichtigen.
Algorithmen lernen ständig aus den Patientendaten und der Forschung und ermöglichen so eine fortlaufende Optimierung der Therapiepläne. So können Behandlungen kontinuierlich aktualisiert werden, basierend auf neuen Erkenntnissen und den sich verändernden Anforderungen.
Verschiedene Datenquellen werden integriert, was eine ganzheitliche und höchstpersonalisierte Pflege ermöglicht. Durch die Zusammenführung von Daten aus medizinischer Bildgebung, Genomsequenzierung, tragbaren Geräten und elektronischen Gesundheitsakten lässt sich ein vollständiges Bild des Gesundheitszustands einer Person erstellen. Ärzte können auf diese Weise frühzeitig Risiken identifizieren, den Verlauf von Erkrankungen präziser beurteilen und proaktiv handeln, um Komplikationen zu vermeiden und die Behandlung zu optimieren.
Mit dem technologischen Fortschritt und dem wachsenden Datenzugang wird die Genauigkeit der Pflege weiter zunehmen.
Einsatz von Robotern und Technologie
Ein weiteres Anwendungsfeld von künstlicher Intelligenz in der Medizin ist der Einsatz von Robotern und automatisierten Systemen. Diese Technologien bieten neue Chancen für höhere Genauigkeit, Effizienz und eine optimierte Versorgung von Patienten.
Moderne Robotertechnologien ermöglichen präzise und komplexe Eingriffe und können in einigen Bereichen sogar die menschliche Leistungsfähigkeit übertreffen. Chirurgen setzen sie ein, um schwer erreichbare anatomische Bereiche zu behandeln, minimalinvasive Operationen mit höherer Präzision durchzuführen und komplexe Eingriffe sicher zu steuern. Echtzeit-Monitoring, Feedback und Anpassungen während der Operation erhöhen die Sicherheit und reduzieren das Risiko menschlicher Fehler.
Durch den Einsatz intelligenter Systeme werden zahlreiche Prozesse vereinfacht und die Effizienz gesteigert, was zu einer höheren Qualität der Patientenversorgung führt. Routinemäßige und zeitintensive Aufgaben werden automatisiert, wodurch Fachkräfte mehr Zeit für die komplexeren Aspekte der Betreuung haben. Robotik und Automatisierung fördern zudem kontinuierliches Lernen und Verbesserung. Echtzeitdaten lassen sich analysieren und an neue Erkenntnisse anpassen.
Trotz der vielen Vorteile bestehen auch Herausforderungen. Eine enge Kooperation zwischen medizinischem Fachpersonal, Ingenieuren und Regulierungsbehörden ist notwendig, um präzise Vorgaben und Standards für den Einsatz von Robotern und automatisierten Systemen zu schaffen. Fachleute müssen gewährleisten, dass diese Technologien sicher und ethisch in der Praxis angewendet werden.
KI und Datenanalyse in der Forschung
Mit dem exponentiellen Wachstum biomedizinischer Daten stoßen herkömmliche Analysemethoden oft an ihre Grenzen. KI-Algorithmen helfen dabei, komplexe Zusammenhänge aus zahlreichen Quellen zu erkennen – etwa aus Genomik, Proteomik, klinischen Aufzeichnungen oder Lebensstilfaktoren. Durch die Auswertung dieser umfangreichen Datensätze ermöglicht KI den Forschern, neue Biomarker und Krankheitsmuster zu erkennen und bisher unbekannte Risikofaktoren aufzudecken. Diese Erkenntnisse vertiefen nicht nur das Verständnis von Krankheiten, sondern schaffen auch die Grundlage für maßgeschneiderte Behandlungen, gezielte Interventionen und präventive Maßnahmen – mit dem Ziel, die Behandlungsergebnisse für Patienten spürbar zu verbessern.
KI-Lösungen im Gesundheitswesen können zudem den Forschungsprozess beschleunigen und die Entwicklung neuer Medikamente vorantreiben. Der Weg von der ersten Entdeckung bis zur Zulassung eines Medikaments ist normalerweise langwierig und ressourcenintensiv. Smarte Algorithmen durchsuchen jedoch in kürzester Zeit riesige Mengen wissenschaftlicher Literatur, klinischer Studien und molekularer Datenbanken, um vielversprechende Wirkstoffkandidaten rasch zu erkennen.
KI ermöglicht es, komplexe Zusammenhänge zu erkennen und Wechselwirkungen zwischen Substanzen und Zielstrukturen zu prognostizieren, wodurch die frühen Phasen der Medikamentenentwicklung effizienter gestaltet und wertvolle Ressourcen gespart werden. Durch Simulationen können die möglichen Auswirkungen neuer Substanzen auf biologische Systeme vorhergesagt werden, wodurch bereits frühzeitig Informationen über ihre Wirksamkeit und Sicherheitsprofile gewonnen werden. Dank der präzisen Identifikation und Verbesserung von Wirkstoffkandidaten beschleunigt KI den Prozess von der Forschung bis hin zu konkreten Therapieoptionen.
Außerdem erleichtert solche Software die globale Zusammenarbeit in der Forschung. Digitale Plattformen ermöglichen die nahtlose Integration und gemeinsame Analyse großer Datensätze, sodass Wissenschaftler aus verschiedenen Disziplinen und Einrichtungen ihr Wissen bündeln können. Das fördert die interdisziplinäre Forschung und stärkt die Transparenz und Reproduzierbarkeit wissenschaftlicher Ergebnisse.
Eine enge Kooperation zwischen künstlicher Intelligenz und menschlicher Expertise bleibt dabei entscheidend. Während komplexe Zusammenhänge aufgedeckt werden, braucht es die Erfahrung und ethische Weitsicht von Forschern, um die rechtlichen, sozialen und gesellschaftlichen Implikationen von KI verantwortungsvoll zu steuern.
Innovative Telemedizin
Die Telemedizin hat sich rasant weiterentwickelt und bietet heute zahlreiche Möglichkeiten zur höchst effizienten Patientenversorgung. Tragbare Geräte und Wearables ermöglichen eine kontinuierliche Überwachung von Vitalparametern, physiologischen Daten und Verhaltensmustern – bequem von zu Hause aus. Diese Technologien sammeln Echtzeitdaten und nutzen KI-gestützte Tools, um Auffälligkeiten zu analysieren und Gesundheitsdienstleister rechtzeitig zu informieren. Dies kann Krankenhausaufenthalte verringern, die Gesundheitssysteme entlasten und die Behandlungsergebnisse verbessern.

Virtuelle Konsultationen bieten eine flexible Alternative zum Praxisbesuch – besonders für Personen, die aufgrund von Entfernungen, eingeschränkter Mobilität oder anderen Hindernissen einen begrenzten Zugang zur Gesundheitsversorgung haben. Digitale Plattformen erleichtern die Kommunikation und gewährleisten den Informationensaustausch in Echtzeit. So unterstützen sie die Triage, helfen bei der Symptombeurteilung und liefern erste Hinweise für weitere Behandlung. Das verbessert nicht nur den Zugang zur Versorgung, sondern optimiert auch die Nutzung von Ressourcen.
Dank smarter Algorithmen wird die Telemedizin noch präziser und individueller. Während virtueller Konsultationen verarbeiten sie große Datenbanken, klinische Leitlinien und Patientenakten, um den Ärzten evidenzbasierte Empfehlungen zu bieten. Dies fördert präzisere Diagnosen, vereinfacht die Planung der Behandlungen und optimiert das Management von Medikamenten. Ein Beispiel dafür sind integrierte elektronische Patientenakten in US-amerikanischen Primärversorgungszentren, die eine umfassende und koordinierte Versorgung ermöglichen.
Intelligente Tools in der Krankenhausverwaltung und Ressourcenoptimierung
Künstliche Intelligenz im Gesundheitswesen revolutioniert nicht nur die Behandlung von Patienten, sondern auch die Verwaltung von Ressourcen in Krankenhäusern. Durch die Analyse von Daten zu Patientenaufnahmen, Entlassungsmustern, Bettenbelegung und Ressourcennutzung hilft sie dabei, den Bedarf präziser vorherzusagen. So lassen sich Personal, Geräte und Betten effizienter zuweisen, Arbeitsabläufe optimieren und Wartezeiten für Patienten reduzieren.
Digitale Systeme passen die Personalplanung dynamisch an den aktuellen Bedarf an – für eine optimale Auslastung des Teams. Auch bei der Bestandsverwaltung hilft KI enorm: Sie prognostiziert den Medikamenten- und Materialbedarf, verhindert Engpässe und minimiert Verschwendung.
Ein weiterer Vorteil ist die Automatisierung administrativer Aufgaben. Krankenhäuser sind traditionell mit viel Papierkram belastet – von der Aktenverwaltung über die Abrechnung bis hin zur Terminplanung. Mithilfe von natürlicher Sprachverarbeitung und ML übernehmen smarte Systeme Routineaufgaben, extrahieren relevante Informationen aus Patientenakten und automatisieren den Rechnungsprozess. Das senkt nicht nur den Verwaltungsaufwand, sondern verringert auch Fehlerquellen und sorgt für eine höhere Datengenauigkeit.
KI ermöglicht eine datenbasierte Entscheidungsfindung auf Managementebene. Durch die Auswertung komplexer Datensätze – etwa zu Behandlungsergebnissen, Prozesskennzahlen und Versorgungsqualität – erhalten Verantwortliche wertvolle Einblicke. So können sie fundierte Entscheidungen zur Ressourcenzuweisung treffen, Prozesse gezielt optimieren und Qualitätsinitiativen vorantreiben.
KI als Zukunft der Medizin
In den kommenden Jahren werden multimodale KI-Modelle immer besser darin, unterschiedliche Informationsquellen gleichzeitig zu verarbeiten – von Bildaufnahmen und Laborwerten bis hin zu Patientenberichten. Intelligente Systeme werden also früher auf potenzielle Gesundheitsrisiken hinweisen. Die Basis dieser Entwicklung ist die sorgfältige Annotation medizinischer Daten. Ob Röntgenbilder, OP-Berichte oder Arzt-Patienten-Dialoge – erst durch akribisches Labeln entstehen die Datensätze, die KIs trainieren und verbessern.
Gleichzeitig wachsen die Risiken: Die Bekämpfung von Bias in Trainingsdaten, die Entwicklung fairer Algorithmen und die Anpassung regulatorischer Rahmenwerke für lernende KI-Systeme sind essenziell, um das Vertrauen in diese Technologien zu stärken. Auch die Bedrohung durch Deepfakes zeigt, dass der kritische Umgang mit digitalem Content zur Kernkompetenz der Fachkräfte werden muss.
Ein entscheidender Punkt: Urteilsvermögen, Empathie und die Erfahrung von Ärzten sind und bleiben unersetzlich.
Fazit
Für Kliniken und Forschungseinrichtungen wird es immer wichtiger, innovative KI-Lösungen für das Gesundheitswesen verantwortungsvoll zu integrieren. Dabei ist es entscheidend, auf Partner mit fundiertem Fachwissen in KI und Medizin zu setzen. Das sind selbstverständlich führende KI-Medizin-Unternehmen.
Andersen bietet KI-Beratung für Unternehmen und hochwertige Services zur Entwicklung intelligenter Lösungen. Unsere erfahrenen Entwickler arbeiten gemeinsam mit einem klinischen Beirat daran, digitale Produkte zu gestalten, die den hohen Anforderungen der Branche gerecht werden.















